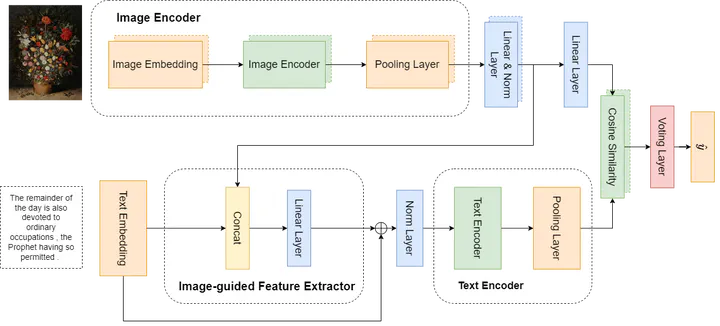
Handle the problem of ample label space by using the Image-guided Feature Extractor on the MUSTI dataset
{kind=link}
Abstract
Among multimodal tasks, olfactory perception remains a largely unexplored field. The two most significant difficulties that need to be overcome are that the label space is ample while the data set size is generally of too small volume. The second is the imbalanced nature of labels in the data set. In this paper, we develop and evaluate our model in the task of predicting the congruence of olfactory experiences between an image and a corresponding text passage on the MUSTI dataset. To solve the label imbalance problem and optimize the process of extracting multimedia images and text with large feature spaces, we propose a model that selectively selects the text features based on image features. By selecting texts that need attention, our model outperforms existing baselines on training and testing data sets.
Type
Publication
In Multimedia Evaluation Workshop